Patterns Before Physics
Ask a large language model for a new scientific equation in plain English, and it will give you one. But it will not be reasoning from physics. It will be reaching for the structural patterns its training data showed it most often — and that is a different thing.
Published May 2026
Reading time 10 min
LLM capabilities evolve rapidly. The behaviour documented here is current — not permanent. Future models may close some or all of the gaps shown below; see the note in “Physics is not the priority” for context.
When a graduate student is asked to invent a new equation for an under-studied physical problem, the first thing they do is not write an equation. They read. They check what the underlying physics requires. They sketch dimensional arguments on a whiteboard. They look at where existing equations succeed and where they fail. The equation, when it finally arrives, is the output of a reasoning process whose primary constraint is physical consistency.
A large language model, asked the same question in plain English, does not do this. It does something else — something faster, more confident, and structurally familiar. The question this study set out to answer was: what, exactly, is that something?
Choosing a problem with room for new equations
To test whether an LLM can generate a genuinely new physical equation, you need a problem where genuinely new equations are still being written. Most formulas for predicting how a sediment particle settles in water have been developed and tuned for quartz and silica sands. Carbonate sands are different. They are biogenic in origin, irregularly shaped, and the literature on them is comparatively thin. That asymmetry is the test: if an LLM is reasoning from physical principles, the relative scarcity of carbonate-specific formulas is exactly the gap it should be able to fill. If it is doing something else, the scarcity will expose it.
The setup. Nine LLM-generated equation pairs — each pair consisting of a drag-coefficient (CD) equation and a settling-velocity (ω) equation — were compared against an experimental dataset of 998 calcareous sand grains from Oahu (Smith and Cheung, 2003), and against a published human-developed equation (Riazi et al., 2020) that an independent 2024 review identified as the most accurate existing formulation for carbonate sediments. Two models, Gemini (Thinking) and ChatGPT, prompted in plain conversational English. Five iterations from Gemini, four from ChatGPT.
Mean relative error vs. experimental data
What the models reached for
The clearest evidence that the models were not reasoning from physics is in the equations themselves. Across both models, every equation rests on the same skeleton — a Stokes-like low-Reynolds term plus a high-Reynolds asymptote — that has been the dominant form in the sediment-transport literature for more than three decades. What varies between the nine equations is the decoration: which exponents on the shape factor, which numerical coefficients, occasionally a hyperbolic tangent or an exponential thrown in. The form is borrowed. The numbers are new.
Each card below shows both the drag-coefficient equation (CD) and the settling-velocity equation (ω) produced by the same model in the same session. The two are presented together because, in physics, they are not separable.
All five equations follow the same structural family.
Across Gemini’s five equations, no single literature paper stands out as the anchor — but they all share the same skeleton. Each one is a low-Reynolds Stokes term plus a high-Reynolds asymptote, with shape-factor corrections grafted onto the coefficients. This additive form has been the dominant template for non-spherical particle drag equations in the sediment-transport literature for more than three decades, going back at least to Haider and Levenspiel (1989) and refined by Cheng (1997), Wu and Wang (2006), and many others since. In its general shape:

And here are all five equation pairs Gemini produced for carbonate sands. Each drag coefficient is a different decoration of the same additive skeleton — different exponents on the shape factor, different numerical coefficients, occasionally a hyperbolic tangent or an exponential thrown in — but the underlying form does not change.
MRE 39.57%

![\omega = \frac{\nu}{d_n}\left[\sqrt{\left(\frac{10.5}{\Psi}\right)^2 + 1.1,\Psi^{1.5} D_{*}^3} - \frac{10.5}{\Psi}\right]](https://latentscholar.org/wp-content/ql-cache/quicklatex.com-4bad458544804da996199d0593587700_l3.png "Rendered by QuickLaTeX.com")
MRE 93.80%


MRE 20.72%

![\omega = \frac{\nu}{d_n}\left[\sqrt{\left(\frac{11.5}{\Psi}\right)^2 + \frac{1.05 D_*^3 \Psi^{0.5}}{1 + 0.2(1 - ER)}} - \frac{11.5}{\Psi}\right]](https://latentscholar.org/wp-content/ql-cache/quicklatex.com-0cf84963db687902c434d33115b5c54c_l3.png "Rendered by QuickLaTeX.com")
MRE 25.28%

![\omega = \frac{\nu}{d_n}\left[\sqrt{\left(\frac{11.2}{\Psi^{1.1}}\right)^2 + \frac{1.04,D_{*}^{3}}{\Psi^{0.5}}} - \frac{11.2}{\Psi^{1.1}}\right]](https://latentscholar.org/wp-content/ql-cache/quicklatex.com-35a2758a0a395f8c649a263a8db7294c_l3.png "Rendered by QuickLaTeX.com")
MRE 26.09%
![C_D = \frac{24}{Re}\Psi^{-1.5} + \frac{0.5}{\Psi^{2.3}}\left[1 - e^{-0.02Re\Psi}\right]](https://latentscholar.org/wp-content/ql-cache/quicklatex.com-207dd7d2ebe2c4f37f74a706f17fede2_l3.png "Rendered by QuickLaTeX.com")
![\omega = \frac{\nu}{d_n}\left[\sqrt{\left(\frac{11.5}{\Psi^{1.2}}\right)^2 + \frac{1.02,D_{*}^{3}}{\Psi^{0.6}}} - \frac{11.5}{\Psi^{1.2}}\right]](https://latentscholar.org/wp-content/ql-cache/quicklatex.com-b7385a3dd2be305a0b0b23910d384f12_l3.png "Rendered by QuickLaTeX.com")
All four equations follow the same structural family.
Where Gemini drew from the general literature template, ChatGPT did something more specific: every one of its four equations matches the exact form Haider and Levenspiel proposed in 1989. Same skeleton, same structural slots, only the numerical decorations differ between iterations:

Each ChatGPT pair below carries the same skeleton, with different coefficients:
MRE 23.22%


MRE 41.70%


MRE 59.21%


MRE 60.41%


Two architectures, two model families, nine prompts. The result is the same: an existing skeleton with new numbers attached. The model has not invented anything. It has retrieved the dominant pattern from its training distribution and decorated it.
Two questions, no coupling
In physics, the drag coefficient and the settling velocity are not independent quantities. A particle settles at exactly the velocity at which gravity balances drag. That force balance is what defines the settling velocity in terms of CD — meaning the two equations are mathematically linked. A human researcher writing one would derive the other from it, or at minimum verify that the pair is consistent under force balance.
The LLMs did not do this. The drag-coefficient equation and the settling-velocity equation in each card above were generated as separate answers to separate prompts. No coupling between them is enforced. Compare any pair within a single card and you will not find CD and ω that satisfy force balance for the same particle. The models treated two physically linked questions as two independent text-generation problems — which is itself a signature of the failure mode this post is documenting. The physics that ties CD and ω together is the kind of constraint a reasoning system would maintain. A pattern-matching system would not, and did not.
The numbers
Each of the nine generated equation pairs was evaluated against the experimental settling-velocity dataset using mean relative error (MRE). The human-developed benchmark of Riazi et al. (2020) is included for comparison.
All errors measured against the settling-velocity equation derived from each model’s own drag-coefficient output, evaluated against the experimental dataset.
The endpoints
Three equation pairs are worth looking at together: the human benchmark, the best LLM pair, and the worst. The contrast is the story.


In Gemini 2, the Corey shape factor sits in the equation in a position that inverts its physical role. The equation is well-formed, dimensionally consistent, and structurally similar to the rest. It is also wrong about basic physics in a way that an expert would catch in seconds. The same model produced both this and the lowest-error LLM equation in the study, in successive prompts. There is no internal consistency check connecting one attempt to the next.
What the equations actually do
The divergence between LLM equations and the physical reference becomes most visible at the limits of particle shape. For nearly spherical particles, most equations cluster near the established curves. As particles become more irregular — the regime where carbonate sediments actually live — the LLM equations spread out, and several of them leave the physical envelope altogether.
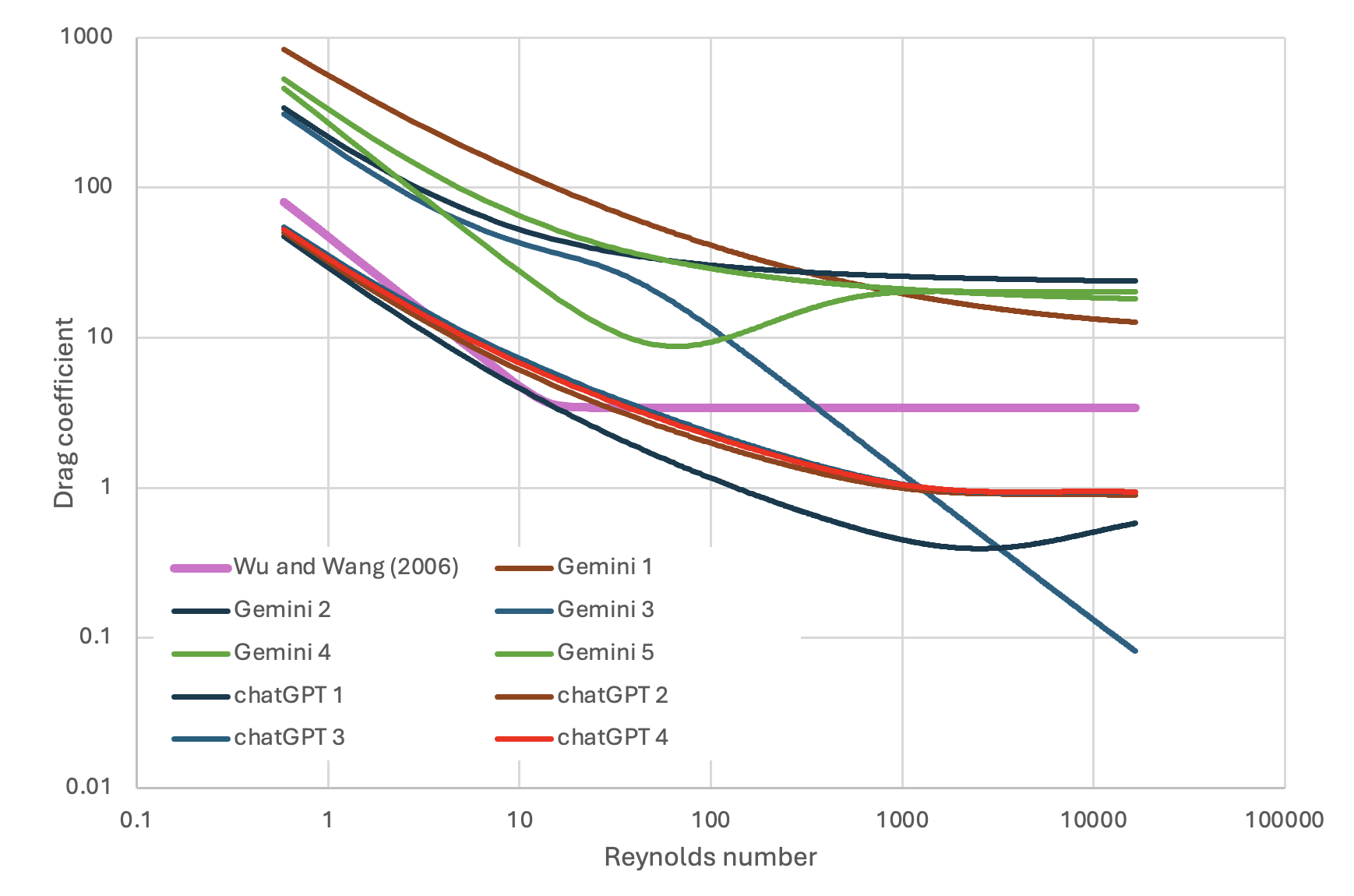
At low irregularity, statistical pattern-matching and physical reasoning produce similar-looking answers because the patterns embedded in the training data do encode the physics for that regime. At high irregularity — the part of the problem the LLM was supposedly asked to solve — pattern-matching and physical reasoning come apart, and what the LLMs return is a fan of inconsistent extrapolations from a literature that was written for a different material. Notice in particular that several curves — including the best-performing Gemini 3 — continue to fall at high Reynolds numbers when they should be approaching a constant asymptote. The equations have the right skeleton but the wrong asymptotic behaviour.
Three things you can see in the output
Each of the following is visible in the data itself, not inferred from outside. Together they describe a specific failure mode that recurs under casual prompting.
Physics is not the priority
The most useful way to read this study is not as a verdict on what LLMs can do, but as an observation about what they do when no one is watching. Asked in plain English to invent a new scientific equation, today’s general-purpose LLMs do not start from the physics. They start from the most common structural patterns in their training data and decorate them with shape-factor terms. The output is fluent, dimensionally consistent, and almost always wrong by an order of magnitude that a domain expert would notice immediately.
A model that produces a manifestly nonsensical equation is easy to dismiss. A model that produces a plausible-looking equation that quietly violates the physics is harder to catch — and more consequential when missed.
The gap between human and LLM equation-writing in these results is not really a gap of capability. It is a gap of priority. A human writing an equation for sediment settling cannot help but think about whether the equation behaves correctly in limiting cases — what happens as the particle approaches a sphere, what happens at very low Reynolds number, what happens when the shape factor goes to zero. These checks are not separate from writing the equation; they are the constraints that shape what gets written in the first place. An LLM, prompted casually, has no such constraints. It optimises for the next plausible token. When the prompt asks for a “novel equation for carbonate sands,” novel turns out to mean a familiar structure with different numbers, and for carbonate sands turns out to be a label rather than a constraint.
This is the central observation. The models are not failing to access physics; they are not reaching for it. Under casual prompting, physical consistency is simply not in the objective function. Statistical fluency is.
- Physical consistency — the equation must respect conservation laws, dimensional homogeneity, and the symmetries of the system it describes.
- Correct limiting behaviour — the equation must give the right answer in regimes where the right answer is already known (low Reynolds number, spherical particles, zero shape factor).
- Causal grounding — the relationships between variables must reflect actual physical mechanisms, not statistical correlations from one regime extrapolated to another.
- Internal coupling — equations that describe related quantities (such as drag coefficient and settling velocity) must be consistent with each other under the physical laws that link them.
- Validation against data — the equation must be tested against experimental measurements, with discrepancies treated as evidence of error rather than acceptable variation.
None of these are in the LLM’s objective function under casual prompting. The model produces a sequence of tokens that is statistically plausible given the prompt and the training distribution. Whether the resulting equation respects any of the five constraints above is a question the model never asks.
The pattern documented here may not be permanent. But it is the default that the current generation of general-purpose LLMs returns under casual prompting, and that default is what most users will see most of the time, until something in the model’s objective function changes to put physical consistency on equal footing with statistical fluency.
As of March 2026, large language models prompted in plain English generate scientific equations by reproducing the structural patterns most represented in their training data rather than by reasoning from physical principles. The resulting equations are fluent and well-formed; they are also unreliable, sometimes physically inverted, internally uncoupled, and consistently outperformed by equations written by humans whose primary constraint is physical consistency rather than statistical fluency.
Methodology and sources
Two LLMs were used: Gemini in Thinking mode and ChatGPT (free tier), both queried on 11 March 2026. Each model was prompted, in plain conversational English, to produce both a drag-coefficient equation and a settling-velocity equation for carbonate sand particles, using a fixed list of physical parameters (particle dimensions, Corey shape factor, nominal diameter, specific gravity, kinematic viscosity). The two equations were generated within the same session per model but as separate prompts — five iterations for Gemini, four for ChatGPT, for nine equation pairs in total.
Performance was measured against the experimental dataset of Smith and Cheung (2003), 998 calcareous sand grains from Oahu, Hawaii. The human benchmark is the equation of Riazi et al. (2020), identified by Chen et al. (2024) as the most accurate existing formulation for carbonate sediments. Reference comparisons for the drag-coefficient plot use Wu and Wang (2006). The pattern-anchor analysis identifies Haider and Levenspiel (1989) as the specific historical form ChatGPT’s equations follow; Gemini’s equations share the broader additive Stokes-plus-asymptote template that has been dominant in the sediment-transport literature since the late 1980s, without pinning to a single named source.
Selected references
Cheng, N. S. (1997). Simplified settling velocity formula for sediment particle. Journal of Hydraulic Engineering, 123(2), 149–152.
Haider, A., & Levenspiel, O. (1989). Drag coefficient and terminal velocity of spherical and nonspherical particles. Powder Technology, 58(1), 63–70.
Riazi, A., Vila-Concejo, A., Salles, T., & Türker, U. (2020). Improved drag coefficient and settling velocity for carbonate sands. Scientific Reports, 10(1), 9465.
Smith, D. A., & Cheung, K. F. (2003). Settling characteristics of calcareous sand. Journal of Hydraulic Engineering, 129(6), 479–483.
Wu, W., & Wang, S. S. (2006). Formulas for sediment porosity and settling velocity. Journal of Hydraulic Engineering, 132(8), 858–862.
Chen, J., et al. (2024). Experimental study on the settling motion of coral grains in still water. Journal of Fluid Mechanics, 990, A15.
Cite this post
If you are referring to this analysis in academic or technical writing, please use one of the formats below. Note: the URL placeholder latentscholar.org/patterns-before-physics/ should be replaced with the actual published URL once the post is live.
@misc{latentscholar2026patterns,
author = {{Latent Scholar}},
title = {Patterns Before Physics: What {LLMs} Reach For When Asked to Invent a Scientific Equation},
year = {2026},
month = {May},
howpublished = {Latent Scholar Research Notes},
url = {https://latentscholar.org/patterns-before-physics/}
}